从作业中截取了部分内容,对表现较好的单个预训练模型进行了测试,从中选出几个进行多模型特征的拼接与测试,并从图片增强、增加特征向量、特征向量拼接三个方面尝试对分类数据进行改善,尽管最后的结果没有达到预期目标,与单模型差距较小,但我认为实现思路大致正确,在类似问题的处理中仍然可以考虑这些处理方法。
一、项目背景
如今,狗已经成为人们生活中不可或缺的伙伴,它们给我们带来快乐、陪伴和安慰。许多家庭视狗为家中的一员,照顾它们并与它们建立深厚的情感联系。而为了防止交易过程中的消费者因品种问题而受骗的现象,狗的品种识别也成为一项重要的任务。
本项目旨在使用预训练神经网络,以Stanford Dogs(斯坦福大学犬类数据集,包含了来自世界各地120种狗的图片)为训练样本,从纯视觉角度实现对120种犬类分类的目标,提供更加准确的犬类分类方案。
二、技术路线
2.1 项目准备
在开始任务前,首先对犬类分类任务进行了调研,通过在IEEE等学术期刊及其他网站上查询相关任务,了解了常用的训练模型及方法。调研后发现,使用较多的方法是通过一个预训练模型,对图片进行特征提取,再连接一个全连接神经网络,获得120种类的各个概率结果并以最高的作为预测结果。同时发现,使用比较多且效果较好的有resnet50、Inceptionv3以及近年在视觉邻域比较出名的vision transform这几种模型。
ResNet-50 [1]是一种深度残差网络模型,通过引入残差连接解决了深层网络难以训练的问题。它具有50个卷积层,并且使用了残差块来构建网络结构,每个残差块包含了两个或三个卷积层,其中间会有跳跃连接,可以直接将输入信息传递到输出,避免了信息损失。该模型在图像分类、物体检测等计算机视觉任务上表现出色。
Inception V3 [2]是一种卷积神经网络模型,主要用于图像分类和目标检测任务。该模型的特点是采用了多尺度卷积的思想,通过不同大小的卷积核来提取不同尺度的特征,并将它们进行拼接。此外,Inception V3 还使用了批归一化和辅助分类器等技术来加速训练和提高模型性能。Inception V3 在 ImageNet 数据集上取得了很好的图像分类效果。
Vision Transformer[3]是一种基于自注意力机制的视觉模型,将图像划分为一系列的小块,然后将这些图像块作为序列输入到 Transformer 模型中进行处理。通过自注意力机制,ViT 模型可以捕捉全局上下文信息,并学习图像内部和不同部分之间的关系,在图像分类、目标检测和语义分割等任务上取得了令人瞩目的成果。
2.2 实验说明
为了使用更好的配置以加快模型的训练,我将代码和数据均部署在Kaggle上。在实验中,我将数据集中每一种类下的图片按照8:2的比例进行划分,再拼接成训练集和测试集,从而保证不会出现某种类数据过多或者过少的现象发生。
设置batch大小固定为64,并在载入DataLoader(数据加载器)时使用shuffle=True来随机打乱数据顺序,以增加模型的泛化能力。同时为了保证模型在训练中完全收敛且更好地记录训练中的准确率、损失率的变化,设置训练总轮数为200次且不使用早停法。使用的其他配置如下所示:
预训练模型:VGG19,Densenet121,Resnet50,Inception v3,Vision Transform(ViT-L/16)
图像增强:随机水平翻转、随机垂直翻转、随机添加高斯噪声
损失函数:CrossEntropyLoss(交叉熵损失函数)
优化器:SGD(随机梯度下降法),Adam(自适应梯度下降法),尝试使用余弦退火策略(其中一个周期的迭代次数为模型训练的总轮数)
此外,在NLP领域中,有一些关于多模态学习的方法,即通过多种类型的预训练模型分别处理某一种类型的输入信息(如使用BERT处理文本信息,使用VGG处理图片信息),再将输出的特征向量拼接作为输入信息进行训练。因此,我尝试结合该领域的思想,使用类似的方法,利用多个模型来处理图片信息,并将其结合,最终形成如图1的实验流程思路。
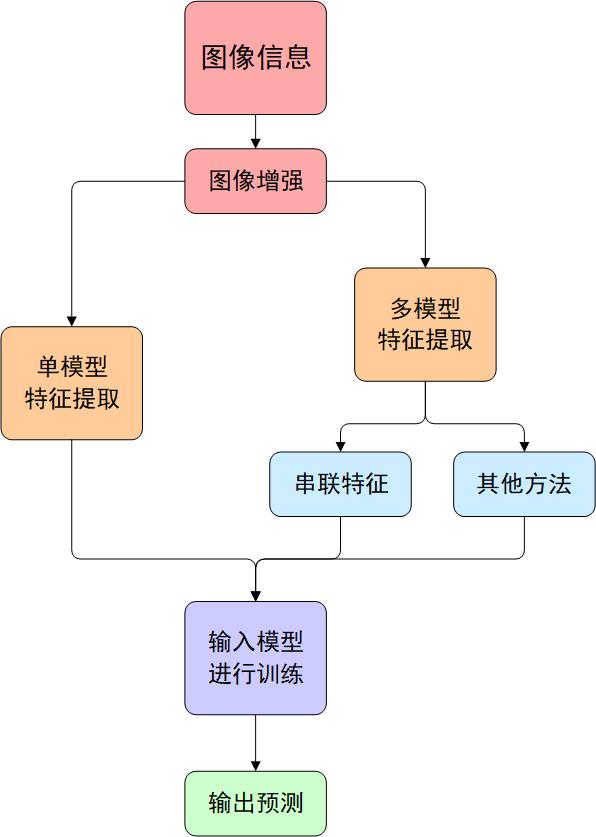
其中,这两种方式输出的维度不同,所以输入模型时需要设置合适的全连接神经网络,如单模型时输出维度为1000维,则模型则为单个全连接层即可,否则模型的复杂程度提示,可能会出现过拟合现象;而多模型则一般不小于2000维度,此时可以设置两层全连接层,并尝试使用dropout来减小过拟合的风险,使用BatchNorm1d来提供模型的鲁棒性。
2.3 代码实现
根据上文中提到的实验流程,代码也分为相对应的几个部分,这里就着重从图像增强、特征提取和模型训练三个方面对代码进行简单介绍。
2.3.1 图像增强
首先依次读取图片文件夹,以每个文件夹上标出的名字作为当前文件夹下图片的标签。由于直接读取大量的图片数据集可能会导致内存不足,所以先将所有图片的路径和对应的标签全部读取到数组中。为了防止划分训练集和测试集时存在部分类别的数据过多或过少的情况,在读取同一文件夹下的图片结束后直接以8:2的比例进行划分数据集。
随后定义好图片的预处理函数。利用pytorch提供的transforms库,通过RandomHorizontalFlip和RandomVerticalFlip对图片均以0.1的概率进行水平翻转和垂直翻转。同时也定义了一个高斯噪声函数np.random.normal,以给定的均值(0)、方差(25)和概率(0.1)给图片随机添加噪声。这些操作主要是为了增加特定特征的动态范围,通过一定的干扰来提高模型的泛化能力和鲁棒性。
需要注意的是,模型的图像输入大小并不完全相同,大部分都是2242243的输入大小,但像inception的大小就为2992993,所以处理时需要分成两类,一类将图片通过Resize和CenterCrop固定到224的大小,另一类则是固定到299的大小。
2.3.2 特征提取
在特征提取中就开始分为两种方案:单模型和多模型。为了更好的简化测试流程,我将每种类型的预训练模型导入之后,为每个模型定义了对应的特征提取函数,读取到图片后只需要先对图片进行预处理,再调用对应的模型并输出最后一层的特征向量即可。对于单模型,只需要调用单个函数即可;对于多函数,则需要调用多个相应的函数,并通过torch.cat将函数返回的特征向量进行串联拼接即可。
2.3.3 模型训练
由于前文中提到的单模型和多模型输出的特征向量维度不同,这里也需要定义两种不同的全连接神经网络。对于单模型,只需要使用单层全连接层即可,对于多模型则需要先将维度降到1024,再输出为120维的类别,两层全连接层之间还可以添加BatchNorm1d和Dropout层以减少模型的过拟合现象。
对于模型训练,我选用了SGD和Adam两种优化器进行实验,由于两种模型的深度不同,所以两种优化器最后的效果可能各有优劣。同时,我也尝试使用了余弦退火策略,其下降周期设置为训练总轮次,这样既可以在训练初期就以较快的速度实现模型的收敛,也可以防止后期中训练次数过多出现的过拟合现象。
2.4 实验过程
在实验中首先对于一些常用的预训练模型,进行初步的测试,在不使用图像增强的情况下,以SGD(lr=0.001, momentum=0.9)或者Adam(lr=0.0001, weight_decay = 0.001)的参数时取最佳的训练结果作为对应模型的测试结果。从测试结果中抽取前两至三个表现最好的模型进行多模型训练,并选取其中表现最好的模型进行图像增强、余弦退火等其他方法和参数的修改尝试。
2.5 实验结果
在初步的训练结果中发现,VGG19,Densenet121的准确率都基本保持在86%左右,而Resnet50可以达到88%左右的准确率,Inception v3和ViT则更是可以达到93%和96%左右的准确率的水平。详细结果如表1所示(只展示准确率最高时的各项参数)。
| 模型 | 优化器 | Accuracy | Precision | Recall | F1 score |
|---|---|---|---|---|---|
| VGG19 | SGD | 87.0255% | 87.6010% | 87.0255% | 86.9267% |
| Densenet121 | SGD(余弦) | 86.8813% | 87.3749% | 86.8813% | 86.7160% |
| Resnet50 | SGD(余弦) | 88.4190% | 88.9203% | 88.4190% | 88.3540% |
| Inception v3 | SGD(余弦) | 93.6088% | 93.8028% | 93.6088% | 93.5928% |
| ViT-L/16 | SGD | 96.9929% | 97.0363% | 97.0029% | 96.9045% |
可以看到ViT和Inception的效果都是要好于其他模型的,所以将这两个模型单独提取出来,进行多模型的测试。这里需要先利用之前ViT和Inception提取的图片特征,将同一张图片的特征串联拼接成一个2000维度的向量并进行测试。多模型的测试结果如表2。
<tr>
<td>模型</td>
<td>优化器</td>
<td>Accuracy</td>
<td>Precision</td>
<td>Recall</td>
<td>F1 score</td>
</tr>
<tr>
<td rowspan="4">ViT + Inception</td>
<td>SGD</td>
<td>96.9929%</td>
<td>97.0363%</td>
<td>97.0029%</td>
<td>96.9045%</td>
</tr>
<tr>
<td>SGD(余弦)</td>
<td>96.9207%</td>
<td>96.9828%</td>
<td>96.9207%</td>
<td>96.9188%</td>
</tr>
<tr>
<td>Adam</td>
<td>97.0589%</td>
<td>97.1347%</td>
<td>97.0889%</td>
<td>97.0799%</td>
</tr>
<tr>
<td>Adam(余弦)</td>
<td>97.2129%</td>
<td>97.2996%</td>
<td>97.2129%</td>
<td>97.1990%</td>
</tr>之后尝试使用图像增强,对图片进行随机水平、垂直翻转和随机添加高斯噪声,再进行特征提取并训练。同时为了尝试提供较多的图像特征,我尝试使用将获得的原始图像特征与增强后的图像特征再结合,形成一个4000维度的特征向量。准确率最高的结果如表3所示。
| 图像 | 优化器 | Accuracy | Precision | Recall | F1 score |
|---|---|---|---|---|---|
| 原图像 | Adam(余弦) | 97.1648% | 97.1648% | 97.1648% | 97.1648% |
| 仅图像增强 | Adam(余弦) | 97.2650% | 97.3350% | 97.2750% | 97.2816% |
| 原图像与图像增强 | Adam(余弦) | 97.3090% | 97.3749% | 97.3090% | 97.3042% |
2.6 结果分析
从结果来看,使用较高准确率的ViT和Inception模型,并结合原图像与
图像增强处理后的特征,所得到的准确率是最高的。同时我记录了训练过程中模型的损失率以及准确率的变化。
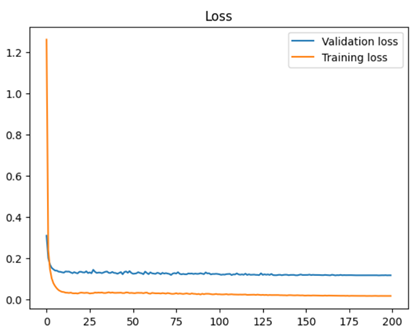
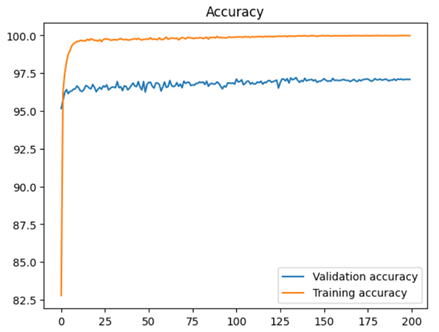
观察训练集的损失率曲线和准确率曲线可以看出,得益于余弦退火策略,模型在训练初期约第10个epoch时就基本收敛,而在训练中后期时学习率变小,使得模型进一步收敛并基本稳定,且没有出现大幅度的震荡现象出现。
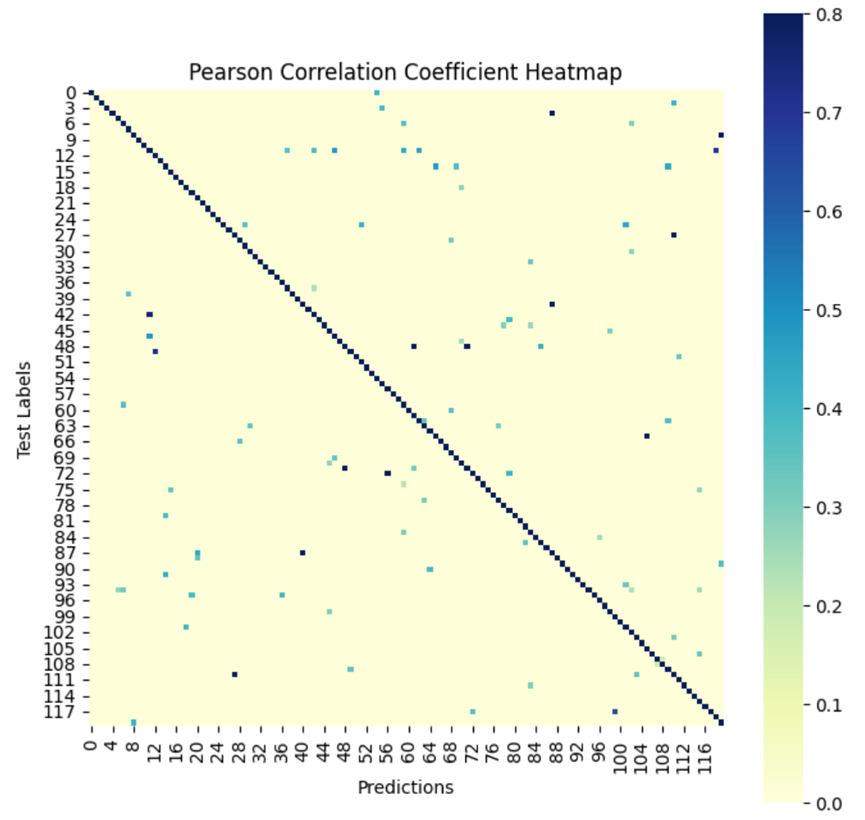
根据预测结果,我使用皮尔逊相关系数热力图进行了可视化(图3所示)。在皮尔逊相关系数热力图中,每个格子的数值表示对应两个变量之间的相关性,颜色越深则表示相关性越强。从图中也可以看出,绝大多数较深色的格子沿左上至右下分布,且颜色较深、相关性较强,表明大部分的预测结果都与实际数据一致,部分数据甚至完全吻合。当然,观察其余部分也可以看出有不少离群点且颜色较浅,说明该部分图像数据被错认为另一种类别的数据。由于分布并没有出现明显的集群或其他模式,所以并不好根据分布进行错误数据的分析。
该方案是在性能表现上具有很多优点。ViT和Inception两个模型具有不同的架构和特征提取能力。通过结合它们的特征,可以获得更多信息和特征表达能力,从而提高整体模型的准确率。同时利用了图像增强处理可以帮助去除或减轻图像中的噪声、干扰或变形等问题,提高模型对输入数据的鲁棒性和抗干扰能力。
这种多模型特征融合的策略可以增强模型的鲁棒性、泛化能力和对复杂场景的理解能力,从而在图像分类任务中取得更好的性能。
2.7 其他尝试
在实验中我发现,当图像的特征向量维度提高时,确实可以提升一定的准确率(尽管在较高准确率的情况下提升较少),所以尝试增大图片的特征向量是可行的。在实验中增大图片的特征向量主要是两种方式,一种是利用多个模型对图像进行特征提取并拼接,另一种则是扩大数据集,在原图像和图像增强后的数据集上进行特征提取。所以这里对这两种方法进行简单的拓展测试,但由于实验结果不够理想,故不作为表现最好的模型方法,仅作为实验探索。
首先是多模型,实际上在表1和表2的对比中就可以看出,多模型在一定程度上是有提升的。于是我尝试使用表1中表现最好的三种模型(即Resnet50、Inception v3和ViT)对图像进行特征提取,并对特征进行拼接并训练。但在实验中发现,准确率不升反降,最终准确率保持在96%左右。
这可能是由于不同的模型可能对同一张图像提取出不同的特征,而这些特征之间可能存在冲突,或者提取出的相同的特征具有不同的分布形式。当将这些特征进行拼合时,可能会引入噪声或者混淆模型。
所以对于上述情况,可以尝试使用其他特征融合方式而非直接串联拼接。通过查找资料发现,可以结合Attention机制[4],通过学习权重分布,将输入特征向量与注意力权重相乘得到加权后的特征向量,再通过求和得到输出张量,表示对输入特征的加权平均值。
不过可能由于代码不够完善,或者采用的方式不够正确,最后输出的准确率仅为96.2037%,并没有取得预期中的表现。
对于扩大数据集的方向,可以采用FPN特征金字塔[5]来实现。将输入的图片以0.5、1、1.5三个尺寸进行缩放并依次提取特征,接下来构建一个图像金字塔,通过上采样和下采样操作将不同尺度的特征进行融合。如果是第一个特征,直接添加到pyramid列表中;否则,将上一级金字塔特征进行上采样(使用双线性插值法),并与当前特征进行下采样(使用最近邻插值法)和扩展操作,得到融合后的特征。然后将融合后的特征添加到pyramid列表中。最后将所有特征进行拼接,就可以得到最终的图像特征。
利用这种方式,当只是用ViT模型提取特征时,可以将特征向量维度从1000维扩展为21000维,极大丰富了特征,实现了从原始图像提取多尺度特征的功能,且保留了不同尺度特征之间的空间信息。
最后其实现的准确率为97.1476%,虽然效果比引入Attention机制略好一些,但还是没有达到理想的效果。
三、项目总结
如果从准确率方面进行评价,那么多模型及多数据集的方式准确率是最高的,较大的特征维度使得模型本身准确率较高,利用余弦退火策略也加快了其收敛速度。但实际上该框架仍然有很大的改进空间。一方面这会出现非常高维度的特征向量,提取特征的耗时、资源占用都会非常高(如ViT提取全部图片特征需要12分钟左右,使用ViT+Inception则需要20分钟,使用FPN需要30分钟),对设备要求也会很高;另一方面,ViT单个模型的表现也非常好,如果使用文中的方法提取更多的特征,尽管会有所提升,但其提升的幅度也很小,多出来的特征并没有带来相应的价值。
要想实现准确率的进一步提升,一昧增加特征向量的维度是不合适的。在之后的探索中,可以尝试使用FPN或者像DANet、GCNet等引入了注意力机制的方法,对特征图进行处理,并最终进行加权融合。这种方法能尽可能的利用图片各种尺度甚至全局信息进行判断,同时不会出现维度爆炸的现象,以使用更可观的训练资源来取得更高的准确率。
参考文献:
[1] He K , Zhang X , Ren S ,et al.Deep Residual Learning for Image Recognition[J].IEEE, 2016.DOI:10.1109/CVPR.2016.90.
[2] Szegedy C , Liu W , Jia Y ,et al.Going Deeper with Convolutions[J].IEEE Computer Society, 2014.DOI:10.1109/CVPR.2015.7298594.
[3] Dosovitskiy A , Beyer L , Kolesnikov A ,et al.An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[C]//International Conference on Learning Representations.2021.
[4] Bahdanau, Cho, and Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR, 2015
[5] Lin T Y , Dollar P , Girshick R ,et al.Feature Pyramid Networks for Object Detection[J].IEEE Computer Society, 2017.DOI:10.1109/CVPR.2017.106.
预览: