本文将简单介绍NeRF和3DGS的模型训练方法以及部分代码可能出现的问题的解决方法,并对物体重建和渲染的效果进行简要评估。
NeRF(Neural Radiance Fields)利用深度神经网络对场景中每个点的辐射传输方程进行建模,通过接收相机视角和射线方向作为输入,神经网络可以映射到物体表面的每个点,并输出颜色和密度值。Nerf能够实现对物体的高质量重建和渲染,包括复杂的几何形状和光照效果。
3DGS(3D Gaussian Splatting)是一种将物体表示为一组高斯函数,并将其投影到2D图像平面上的技术。首先,通过对物体表面进行采样,生成一组高斯函数,每个高斯函数由中心点、协方差矩阵和颜色信息组成。然后,将高斯函数投影到图像平面上,并根据高斯函数的位置和颜色信息计算每个像素的颜色值。通过考虑像素与高斯函数之间的距离和高斯函数的权重,3D高斯泼溅可以得到物体的高质量重建和渲染效果,包括复杂的几何形状和纹理信息的呈现。
准备
在正式开始之前,我们至少需要部署Anaconda,pycharm(jupyter或其他开发环境应该也都可以),vs2017-2019,cuda。
这里需要注意几点:
vs的版本一定是2017至2019之间的!不然后续安装内置的第三方库时会报错!可以只下载一个Build Tools(生成工具)!
cuda也是老生常谈的话题了,经常接触深度学习的肯定都很熟悉了,结果我还是差点翻车了。。太长时间没有装过cuda,而且有很长一段时间都在使用kaggle没在本地跑过,导致安装的时候出现一堆错误...由于我电脑需要使用tensorflow,而tf最新的版本好像也才只支持cuda 11.2(不确定是否向上兼容,查了挺多教程都只安装11.2),再加上卸载安装有点麻烦就一直没动也没准备动,但是3DGS要求cuda在11版本最佳(官方使用11.6,并声称对11版本的bug进行了修复,不确定其他版本的情况),也就是说我只能使用11.1-11.2两个版本的。在pytorch官网(https://pytorch.org/get-started/previous-versions/)查询后发现只有1.9.1版本之前的,遂选择1.9.1安装。
1 | # CUDA 11.1 |
我本来想使用conda进行安装的,但是一直卡在solving environment,差不多半个小时到一个小时,而且不确定是家里网的问题还是什么情况,开了加速器也只有几十k的速度,只要使用pip安装。我也测试了cuda 10.2, torch 1.12.1但是安装后torch有问题就放弃了。
1 | import torch |
以上代码输出True即为成功。
这里还建议安装一下colmap(https://demuc.de/colmap/),下文中使用的NeRF里有包含colmap的工具,但3DGS需要配置一下,下载后将colmap文件夹(D:xxx/xxx/colmap)放在环境变量的用户变量的Path里即可。
NeRF
这里使用的是Instant NGP,使用比较简单,在pycharm中打开对应的项目文件夹后切换到conda环境,只需要安装environment.yml里的库即可。(部分库可能无法在pycharm中下载,pip都可以成功下载)
Github: https://github.com/NVlabs/instant-ngp
注意下载时要仔细阅读README,选择好对应显卡型号的版本下载!
b站也有很多讲解视频,可以看一看基础的使用流程。比如我看的这一篇《五分钟学会渲染自己的NeRF模型,有手就行!》 里面有部分写好的工具及代码(ffmpeg和colmap,用于切分视频和建立对应的相机位姿),可以根据视频直接进行测试。
运行前只需要调整colmap2nerf.py下的代码,将 video_in 的默认参数调成视频位置,以及video切分的帧率。
1 | parser.add_argument("--video_in", default="D:/xxx/Instant-NGP-for-RTX-3000-and-4000/xxx/xxx.mp4",...) |
再将该代码的运行参数(run configuration)中加入--run_colmap 用于表示对输入视频进行colmap处理。在运行过程中可能会出现缺少detectron2库的情况,pip和conda应该都不能直接下载,需要从Github上拉取detectron2 再进入环境中安装。
我这里先从b站上找了一个手办视频进行了测试。(视频地址:【手办分享】纯享版!寿屋 东海帝皇细节分享与摄影)测试的时候发现中间相机视野切换的时候colmap的相机位姿解算会出问题,所以只使用了开头大概十五六秒左右的片段。我这里先用colmap单跑了一遍,结果大致如下。
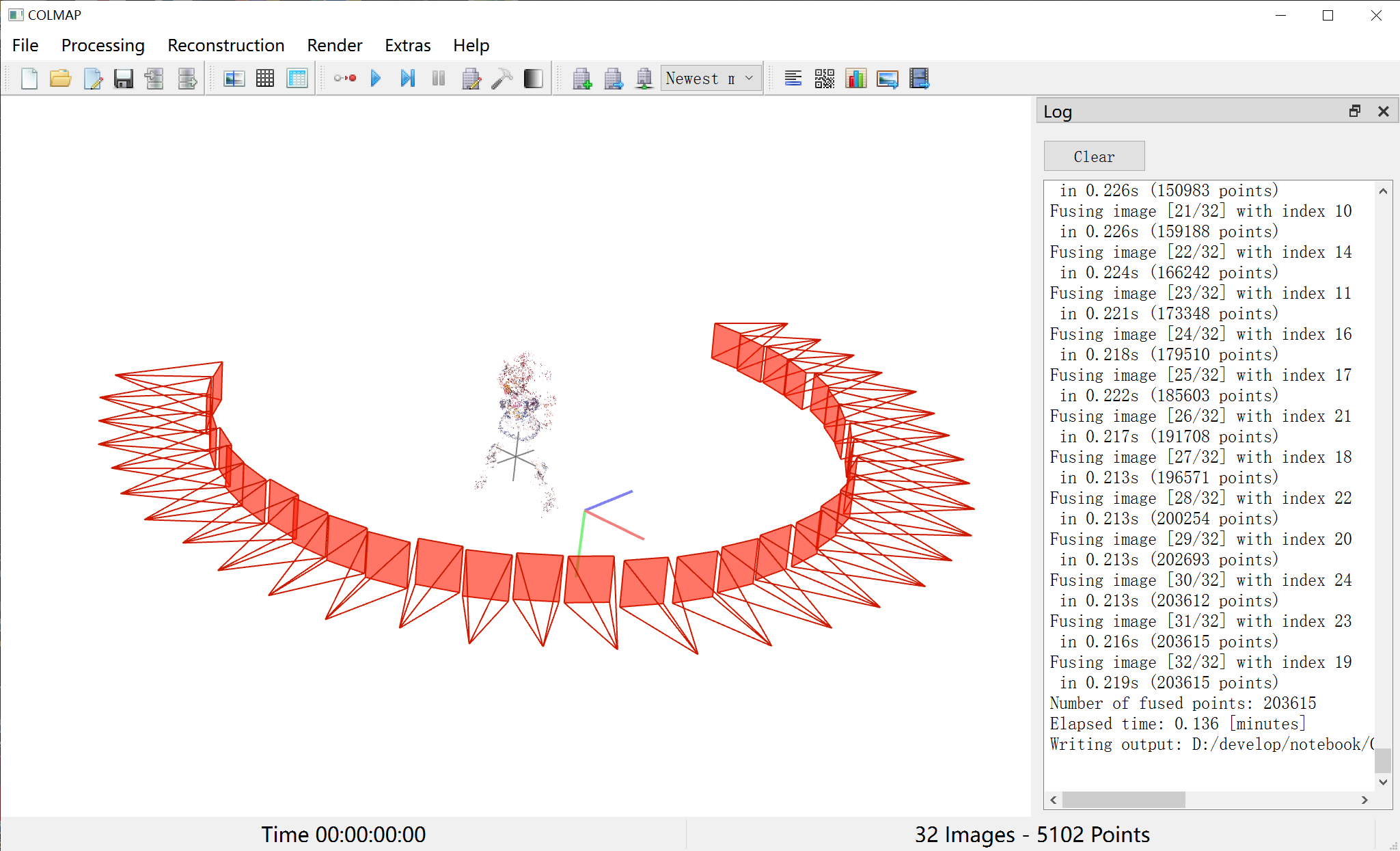
由于物体旋转而非相机旋转,所以相机的位姿看起来还是相当平滑的(但是最好还是相机环绕物体,不然效果确实不算很好,我这里也只是单纯测试一下)。
看到解算基本没问题,接下来就可以放到程序里了,按上面的步骤来,很快就可以在scripts文件夹下生成一个transforms.json 相机位姿文件,复制粘贴到包含原视频的文件夹内,与images(视频切分的对应图片)一起选中,打开instant-ngp.exe并将两个文件拖进去就可以开始训练了。我大概是训练到2万步左右就结束了。实际上发现loss率基本稳定在0.0002左右且画面基本稳定时就可以结束了,大概1万步出头就可以了,如果loss率较高且上下波动较大,可以考虑是colmap解算出了问题,需要重新跑几遍试试,一直不行的话需要考虑更换视频。

perspect1

perspect2

这里使用了crop size剔除了周边一定范围外的背景,保留了中心区域的对象。可以看到,帝皇的右后侧方没有被拍到,所以那一块就散布着很明显的体积雾,如果拍摄能更全一些应该就不会有这种大范围的区域。整体来看,手办的整体形态还原的还是可以的。包括皮肤、衣物、头发、面部表情,表现都不错。不过还是有一些问题的,在gif里看的可能不是很清楚,但是也能隐约看出,物体周围附有有一层薄薄的体积雾,在手指、裙摆以及腿部的边缘还是比较明显的。还有一个问题就是如果再放大一些,可以感觉整体都比较模糊,不过稍微远一些来看效果还是可以的。
3D Gaussian Splatting
和Nerf差不多,也是从github拉下来,pycharm里打开并安装、切换环境即可。
Github:https://github.com/graphdeco-inria/gaussian-splatting
3DGS可能出现的报错会多一点,首先需要使用 pip install 指令安装submodules文件夹下的两个模块diff-gaussian-rasterization, simple-knn,不然后续代码中会出现import error。安装时如果出现c语言编译错误可能需要尝试安装cmake或者Cython模块(不太确定,网上有说这种解决方法但我这里没用),如果翻阅安装信息中出现了 No CUDA runtime is found ,则需要考虑是由于cuda版本与pytorch模块冲突导致的,需要重新检查pytorch版本(有可能安装成了cpu版本),重新安装并按上文中的方法测试pytorch是否正常运行;如果安装信息出现fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! 那么需要重新检查vs(生成工具)版本是否正确,如果有多个版本出现此错误可能需要尝试卸载不合适的版本再测试。
装完后如果有切分好的图片和对应colmap数据就可以直接运行了,如果只有视频的话可以运行下面的脚本,需要在文件中新建一个文件夹(我这里设置的是data)然后放置对应的视频文件,同时需要在文件夹下放置ffmpeg模块(可以从nerf里面直接复制过来使用,也可以从github上拉取),然后将两者的地址分别设置给video_path和ffmpeg_path,再调整fps即可(一般设置为2就行,如果视频里的移动比较快可以设置大一点)。
1 | import os |
网上基本都说装完就可以直接运行了,但是我这里出现了错误NameError: name '_C' is not defined,查阅后发现是diff-gaussian-rasterization下的diff_gaussian_rasterization/__init__.py出现的错误(应该是 num_rendered, color, radii, geomBuffer, binningBuffer, imgBuffer = _C.rasterize_gaussians(*args) ),检查后发现开头的from . import _C 部分莫名被注释了,原代码中是正常的,应该是安装模块出现的问题。去除注释就可以了(不需要重复安装)。
后面还再gaussian-splatting\utils\loss_utils.py中出现错误:mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel) RuntimeError: Expected 4-dimensional input for 4-dimensional weight [3, 1, 11, 11], but got 3-dimensional input of size [3, 938, 192] instead. 可以在报错位置上加入两行代码。
1 | def _ssim(img1, img2, window, window_size, channel, size_average=True): |
这样再运行上述代码即可。在使用视频切分和colmap后就开始了对模型的训练,当训练到7000步时会保存一个ply文件,可以在文件夹下的output\xxx\point_cloud\iteration_7000里查看点云结果来评估效果(中间是随机的名字,在训练结束之后可以更改),训练到30000步时保存文件并结束训练。
训练结束后可以使用下面代码查看训练结果。这里需要添加一个模型可视化的工具(https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/binaries/viewers.zip),将该文件解压到文件夹中即可。
1 | import subprocess |
运行后会出现一个和nerf很像的界面,不过操控方式不同,需要使用WASD控制视角的前后左右移动,IJKL调整视角朝向(用的是FPS操作方式,感觉相比Nerf好麻烦啊真挺难操控的,我一开始弄半天都找不到怎么操作)。
而且我本来想测试上面的视频结果的,但是发现不知道为什么colmap一直运行报错,后面也跑出来了几次,但是模型一直有问题只能放弃了。所以我后面又勉强找了个位置简单拍了一下(家里真找不到什么打光好、位置又宽敞的地方),拍摄的效果质量并不太好,就当对较复杂的不太理想的场景的测试吧。
原理概述
NERF是一种隐式表达方法,它使用神经网络来表示场景中每个点的辐射亮度。NERF的输入是图像+该图像对应的相机位姿5D输入,通过训练神经网络,输出该点对应的颜色和光照信息。这种方式下,场景的三维信息被隐式地编码在MLP的参数中。NERF的优点是可以生成高质量的逼真渲染结果,并且可以处理复杂的光照和材质效果。
3DGS则是一种显示表达方法,它主要关注场景的几何结构和拓扑信息。3DGS通过输入图像+经过SFM方法后生成的稀疏点云,对场景进行建模、重建和分析,并利用三维模型来计算场景的几何属性。3DGS实质就是一种三维点云,其中明确包含物体的属性信息(位置、颜色、不透明度等)。
因此,NERF和3DGS在呈现效果上的区别主要在于它们关注的方面不同。NERF更侧重于逼真的渲染和光照效果,而3DGS更侧重于场景的几何结构和空间理解。详细表现可以看下文中的对比。
效果对比
我这里使用的是我自己的伊蕾娜手办,简单拍了一圈。垫了两张纸是为了尽可能减少强光反射在手办下方的地板上导致的光线影响(虽然好像并没有什么用就是了hhh)。

这里从几个视角简单对比一下效果。
首先是半透明的底座。
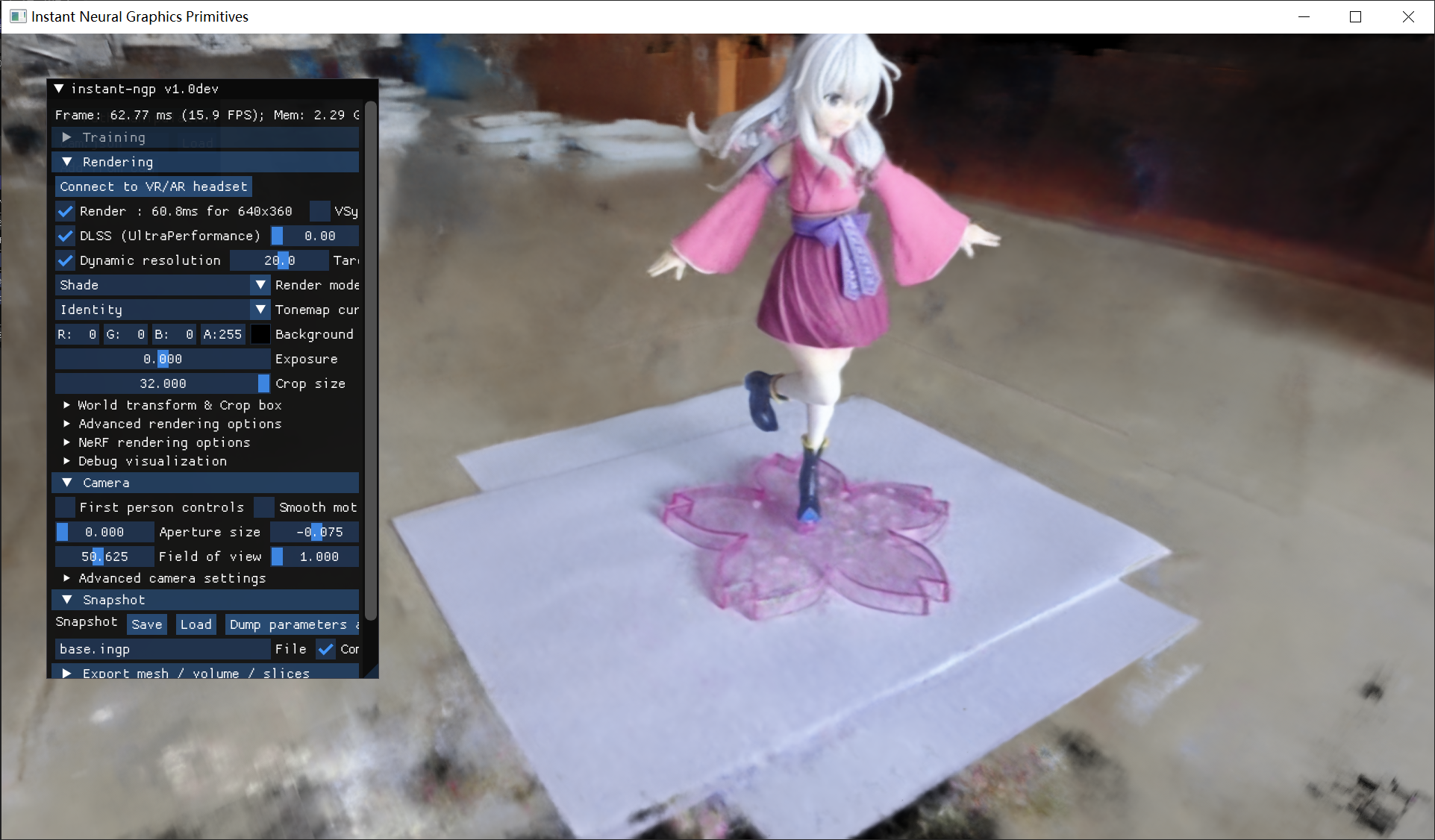
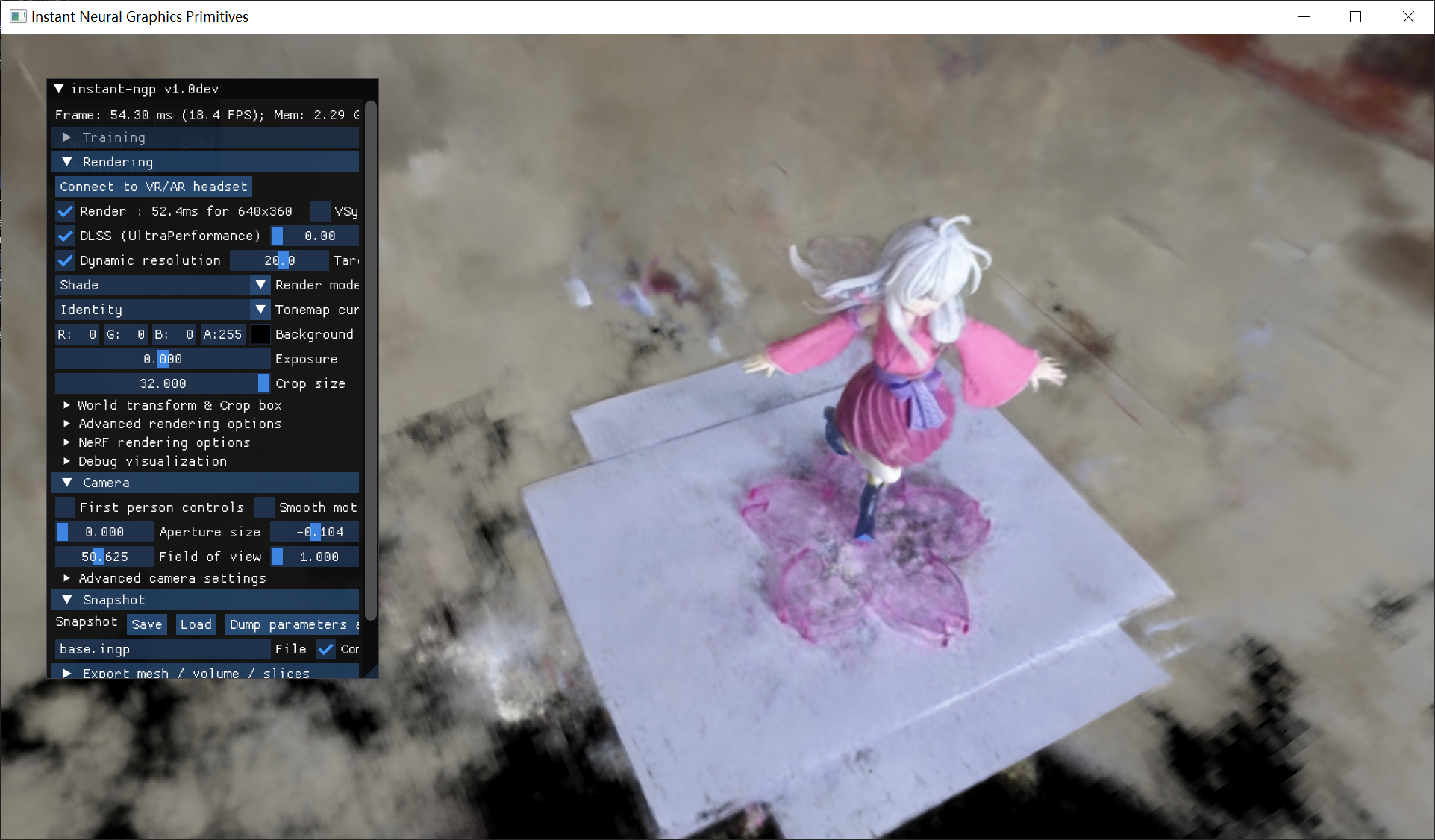
很明显,当视角贴近拍摄视角时底座基本没什么问题,但是一旦移动到高视角就会出现明显的破损现象。
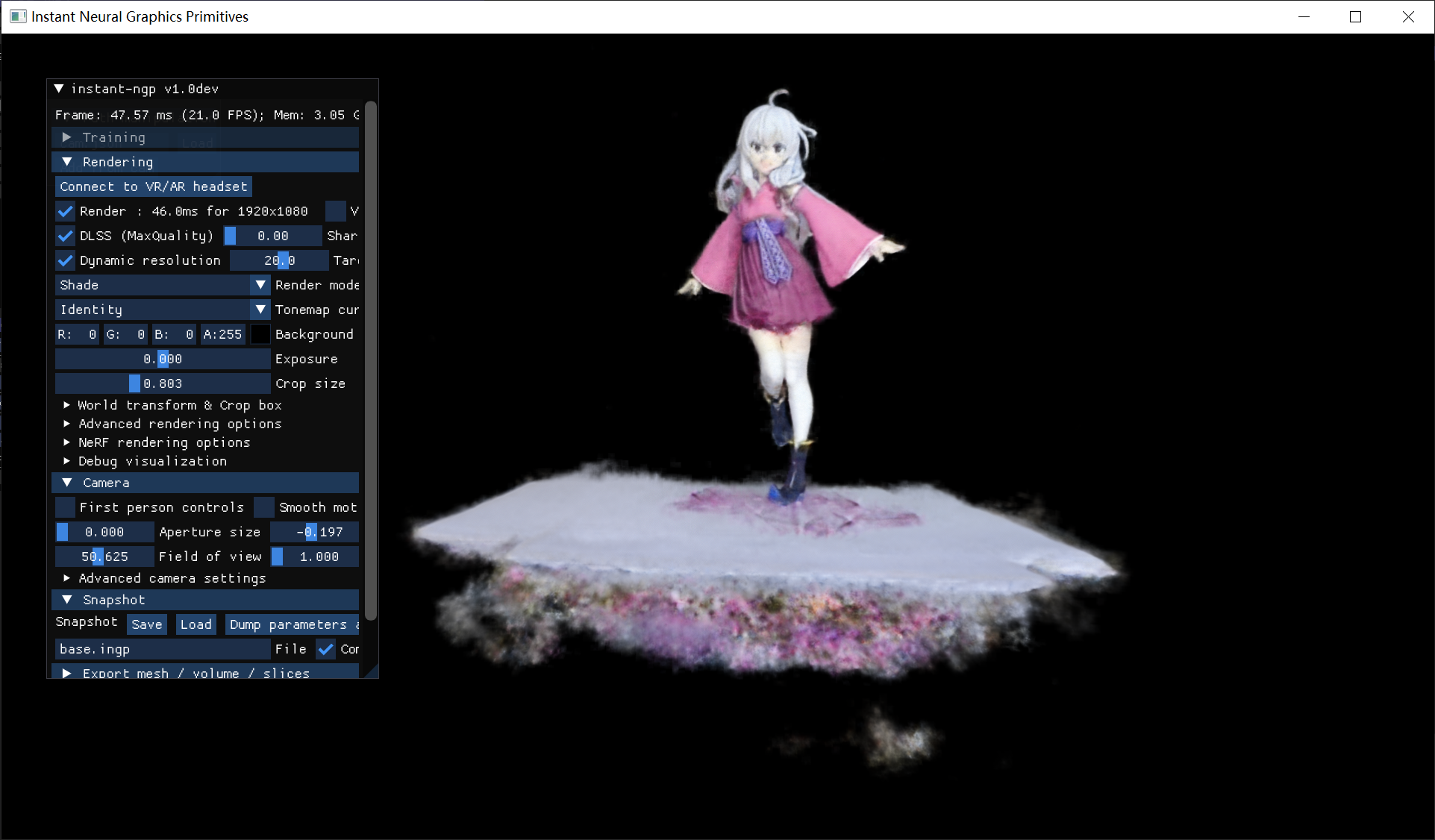
crop size调整后观察平面下方,可以看到底座下方的纸基本是破损的,且在下方有一团雾状区域,颜色与底座颜色近似,这可能是由于其半透明的材质,在模型训练时为了呈现这一特征,就错误地被扩散到平面下方,导致平面的破损。
再来看看3DGS方面。


底座几乎没有破损现象发生,还原的质量相当高!而且周围的地板相对来说也更加平整,整体场景的还原效果也好了不少。再看一眼平面下方。

虽然底下还是会有一部分包含光学属性的高斯体,但是平面是完好无损的,这样在其他角度就基本不会出现破损问题。
接下来对比一下两种方法的光线、明暗的不同处理方法。
NeRF
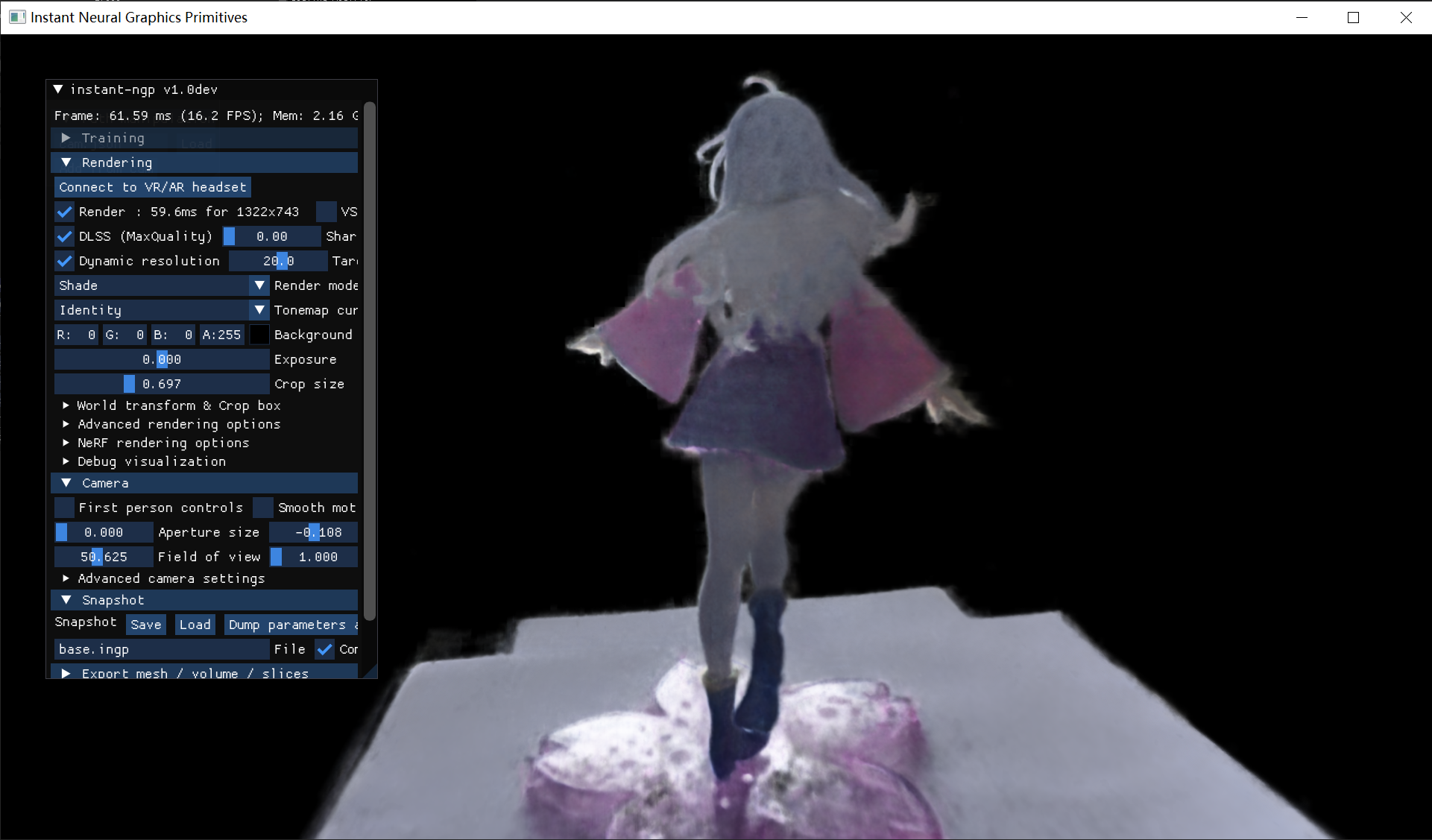
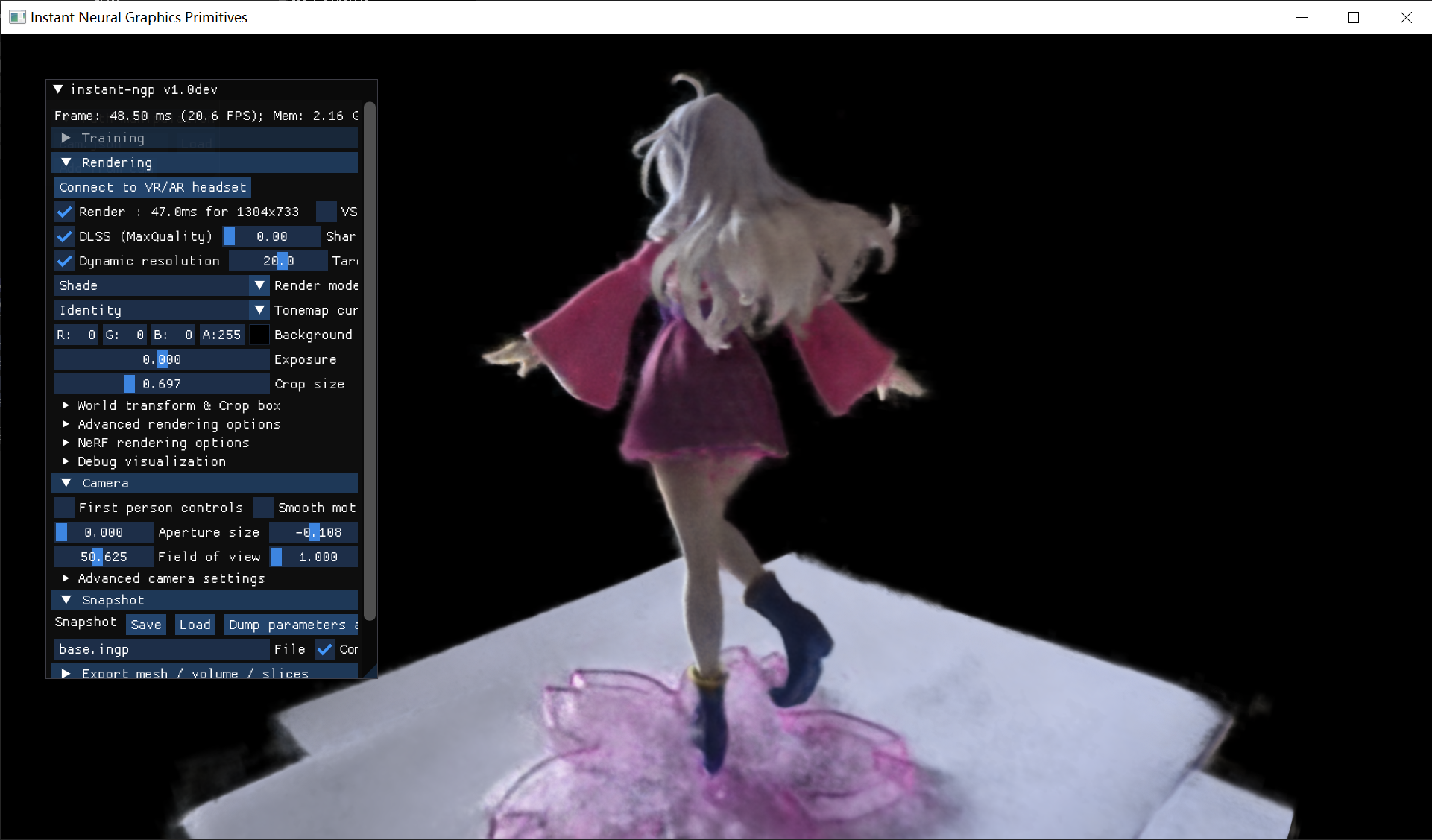
3DGS


在拍摄的时候,从手办背面拍摄时正面有强光,导致相机自动压低曝光,就使手办背面颜色出现失真,出现了大面积的略微偏蓝的灰白色。这里的图片可能看的不是很明显,但是在运行过程中移动视角可以看得清楚一些(太麻烦了所以就没有录视频了绝对不是因为我懒)而在这两种方法重建后可以看出,3DGS在变换视角后,手办背部后方会出现较浅的高斯体,而NeRF则不会出现类似的情况,没有过多的体积雾。
借此可以简单推断一下,在重建过程中,NeRF可以保留物体受到的光照信息,而3DGS更关注物体的结构特点,像这种光照信息往往会以高斯体的形式排除在物体的主要结构之外,如果可以剔除的话,可以说3DGS就能够更好地保留物体的模型结构信息,NeRF就可以用来标注物体表面的贴图。我印象中好像看到有一篇论文就完成了3DGS和NeRF的结合,利用3DGS生成场景的几何模型,然后将这些模型作为输入提供给NERF来生成贴图。
再放大一些对比一下细节
NeRF
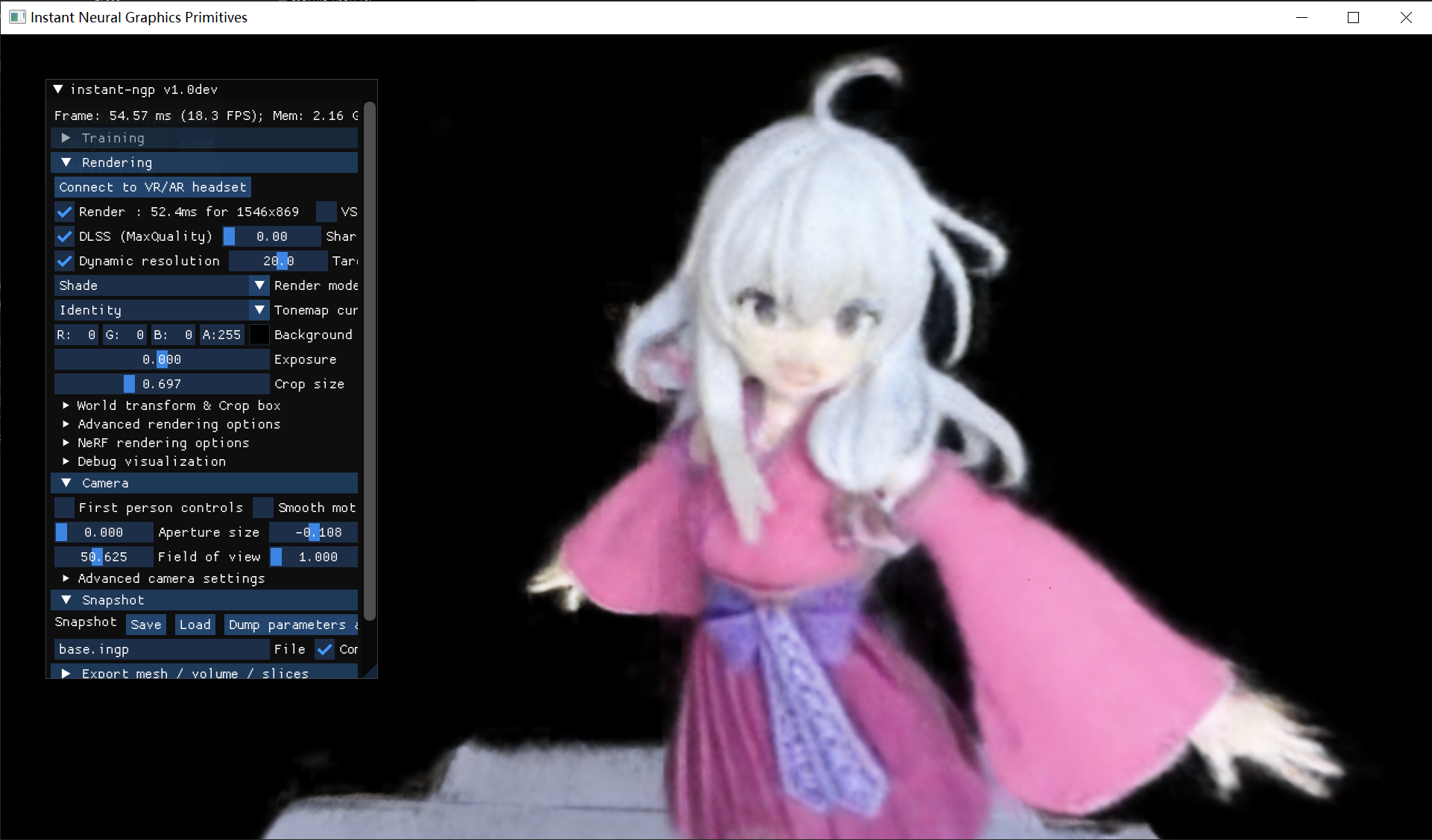
3DGS

这么一对比感觉NeRF跟打了马赛克一样...
3DGS在画面细节上还是挺到位了,手指之间的缝隙明显,裙摆、头发的纹理都相对清晰一些,特别是在面部,3DGS的模型几乎可以说完全符合正式情况。
NeRF对于颜色的还原程度比较高,但缺点就在于模型的体积结构问题较大,比如手、发梢这种较锐利的边缘附近还是很明显的。特别是在下图角度中可以看出,面部是存在比较严重的错位现象的,用mesh的方式呈现则是更加明显了。

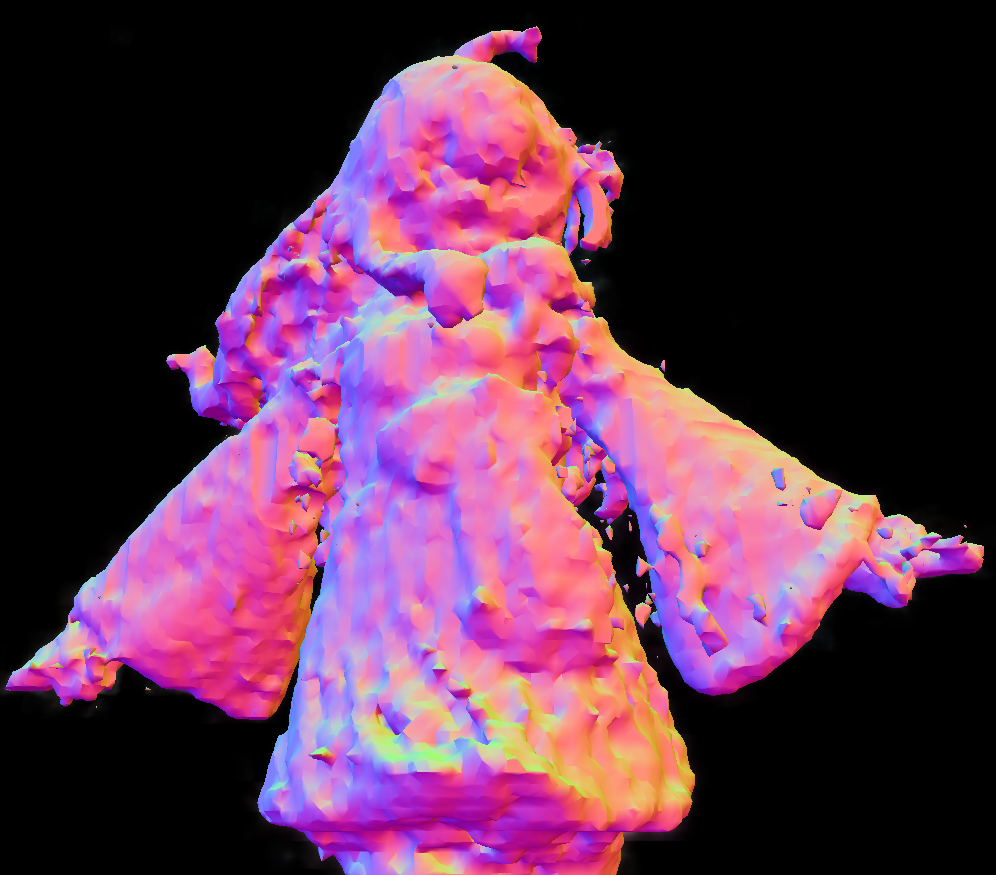
其他方面的小对比:
我用的是3060的笔记本,所以对于性能表现还是相当敏感的。(太拉了以后一定要买张好显卡) 在训练过程中可以感觉出来,3DGS的训练效率比起NeRF确实要高出不少,NeRF练2w步左右大概在20分钟到半个小时左右,而3DGS练完3w步也就十几分钟就结束了,并且在最后结果展示的时候也能感觉出,NeRF展示时更吃性能一点(3DGS打开一点动静没有,NeRF点开风扇直接开转了,任务管理器都不用开就感觉了)。管不得天天看网上各种NeRF必被秒的言论,确实从质量还是速度来说3DGS都具有显著优势。不过这里用的NeRF和3DGS都已经算是比较早而且教程满天飞的那种了,最近经常能刷到一些更精进的模型(比如可以将3DGS转为Mesh的项目),后面有空的话还是尝试尝试复现其他一些有意思的3DGS的论文吧。