最近项目需要做这方面的内容,所以简单讲讲在点云处理方面遇到的一些问题以及可能有效的解决方法仿照一篇论文,改了一点思路,重新实现了代码
点云数据
简单介绍一下点云数据。顾名思义,点云表示的就是给定空间中的一些位置,只是用一定大小的点表示出来更加直观。其一般由xyz位置与RGB构成,一般用txt就可以表示,也可以用pcd、ply等更专用的格式表示。目前比较流行且方便的点云获取方式主要有两种,RGBD深度相机和LiDAR激光雷达,通过扫描空间或者特定的物体就可以得到对应的表面信息。通过观察点云,我们可以很直观的看到空间或物体的特征。
虽然初始获得的点云(Raw Point Cloud)是包含了众多缺陷的,但是这并不影响点云这类数据的优势。相对于体素(Voxel)表达方式来说,点云的储存空间占用更加小,而且在旋转之后仍然可以很好的表达几何信息。相对于网格(Mesh)表达方式来说,点云更加容易获取,而Mesh没有比较直接的获取方式。另外一方面,点云和其他3D格式之间的转换也是相当方便的。
基于点云,我们希望能通过位置、颜色等信息,推测出点云的所属类别、如何分割、完整形状、空间预测以及状态预测等等数据。总之,我们通过这些坐标和颜色做的其实只是一件事,叫做对点云的“理解”。这也是我们希望从低等几何表达向更加智能化的任务迈进的必经过程。这也就引出了点云+深度学习的新型学习模式。
Pointnet模型
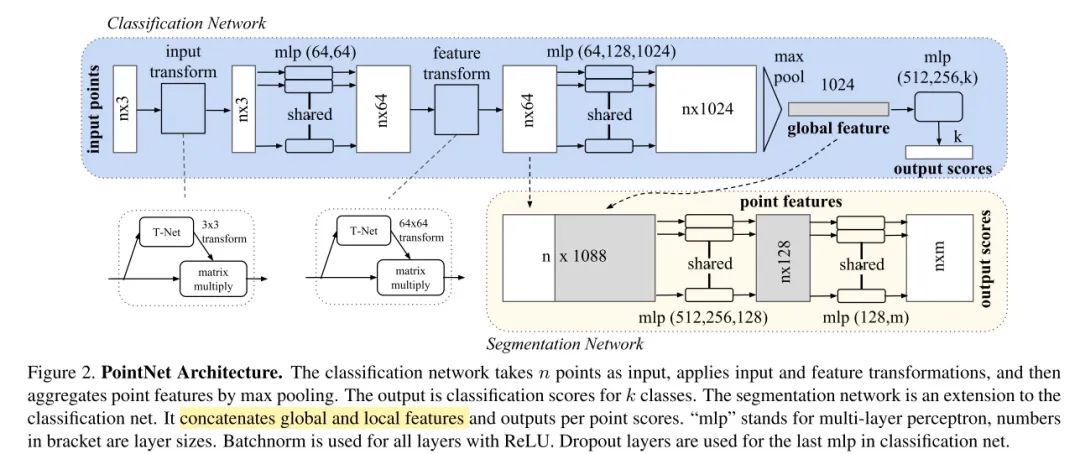
说到点云与深度学习,这就不得不提到pointnet模型,这可以说是基于点云的神经网络的最具开创性的作品,为点云处理提供了一个简单、高效、强大的特征提取器,在点云分类和分割上取得了非常巨大的成就。
img
论文中提出,在欧几里得空间下的点云具有三个特点
1)无序性:点云数据是一个集合,对数据的顺序是不敏感的。这就意味这处理点云数据的模型需要对数据的不同排列保持不变性。目前文献中使用的方法包括将无序的数据重排序、用数据的所有排列进行数据增强然后使用RNN模型、用对称函数来保证排列不变性。由于第三种方式的简洁性且容易在模型中实现,论文作者选择使用第三种方式,既使用maxpooling这个对称函数来提取点云数据的特征。Pointnet网络主要使用对称函数解决点的无序性问题,对称函数就是指对输入顺序不敏感的函数。如加法、点乘、max pooling等操作。假设输入特征为NxD,N表示点数,D表示维度数,在max pooling作用下,取出每个维度上最大值的1xD的向量,每一维特征都与其顺序无关,这样便保证了对于点云输入顺序的鲁棒性。
2)点与点直接存在空间关系:一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。为了能有效利用这种空间关系,论文作者提出了将局部特征和全局特征进行串联的方式来聚合信息。
3)旋转平移不变性:点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。论文作者提出了在进行特征提取之前,先对点云数据进行对齐的方式来保证不变性。对齐操作是通过训练一个小型的网络来得到转换矩阵,并将之和输入点云数据相乘来实现。Pointnet的解决方法是学习一个变换矩阵T,即T-Net结构。由于loss的约束,使得T矩阵训练会学习到最有利于最终分类的变换,如把点云旋转到正面。论文的架构中,分别在输入数据后和第一层特征中使用了T矩阵,大小为3x3和64x64。其中第二个T矩阵由于参数过多,考虑添加正则项,使其接近于正交矩阵,减少点云的信息丢失。
具体的网络结构这里就不再提及了(不过真的很推荐看一看原文)。基于pointnet结构就可以完成很多类型的任务,比如点云配准,物体检测,3D重建,法向量估计等,只需要根据具体任务合理修改网络后几层的结构,利用好网络提取的高维特征。当然,还有有一些缺点,比如局部特征提取能力较差(因为基本上都是单点采样,代码底层用的是2Dconv,只有maxpooling整合了整体特征,缺少不同尺度下相邻点之间的关系)。
Pointnet++模型
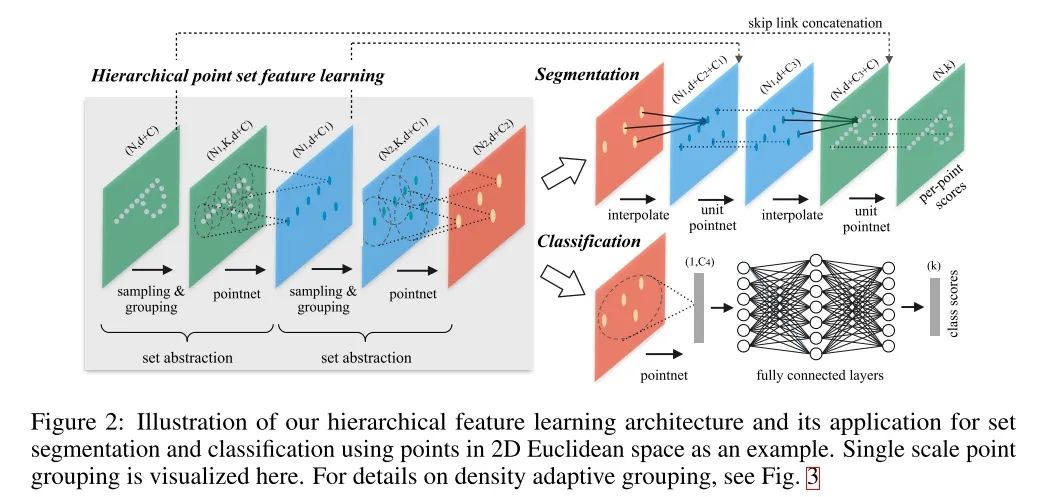
不过,这个缺点在Pointnet++里已经得到了很好的改善。PointNet提取特征的方式是对所有点云数据提取了一个全局的特征。受到CNN逐层提取局部特征的方式的启发,提出了PointNet++,它能够在不同尺度提取局部特征,通过多层网络结构得到深层特征。PointNet++按照任务也分为 classification (C网络)和 segmentation (S网络)两种,输入和输出分别与PointNet中的两个网络一致。首先,比较PointNet++两个任务网络的区别:在得到最高层的 feature 之后,C网络使用了一个小型的 PointNet + FCN 网络提取得到最后的分类 score;S网络通过 skip link connection 操作不断与底层 low-level 信息融合,最终得到逐点分分类语义分割结果。
PointNet++ 的思路与U-Net很相似:利用encoder-decoder结构,逐层提高feature level,在到达最高层之后通过 skip link connection 操作恢复局部信息,从而达到既能获取 high-level context feature 也能获取 low-level context feature。
img
pointnet++主要的贡献就是解决pointnet中局部特征提取的问题。
1)改进特征提取方法:pointnet++使用了分层抽取特征的思想,把每一次叫做set abstraction。分为三部分:采样层、分组层、特征提取层。首先来看采样层,为了从稠密的点云中抽取出一些相对较为重要的中心点,采用FPS(farthest point sampling)最远点采样法,这些点并不一定具有语义信息。当然也可以随机采样;然后是分组层,在上一层提取出的中心点的某个范围内寻找最近个k近邻点组成一个group;特征提取层是将这k个点通过小型pointnet网络进行卷积和pooling得到的特征作为此中心点的特征,再送入下一个分层继续。这样每一层得到的中心点都是上一层中心点的子集,并且随着层数加深,中心点的个数越来越少,但是每一个中心点包含的信息越来越多。
2)解决点云密度不同问题:由于采集时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的。
由于没有local context信息,因此pointnet对复杂的点云没办法处理,只能运用在相对简单一些的场景中进行使用。同时,在分割任务中,需要更加详细的local context信息,也不太适合用pointnet处理。当然,pointNet++也有缺点,其具有一个邻域中心和邻域点云索引的过程,会使速度下降严重,对于局部点云的特征提取起始与pointnet差不多,在这种情况下综合来看还不如pointnet。
人体点云
在了解了上面这些基础知识之后,就可以来深入的看一看人体点云了。这里使用UBV3C数据集为例,该数据集包含了人体点云以及人体骨骼数据(18点)。为了更好的分析人体点云的特点以及后续数据的需要,对点云数据进行预处理,将每个点云赋予一个标签,由其距离最近的骨骼决定,将人体划分为18块区域,结果如下。

这里用随机数生成的各部分颜色,所以有些位置的看起来区分的可能不是很明显
点云分布特征
可以清楚的看到,由于我们在赋予标签时是通过骨骼决定的,标签也就拥有了两种特征:一是聚类特征,同一种标签的点云只会聚集在同一范围内,也就是说不同标签的点云不会侵入到其他标签的范围内,点云间有明显的边界区分;二是距离特征,由于人体的骨骼可以看作刚性连接,相连的骨骼距离几乎是一定的,而与骨骼连接所对应的相连标签也是存在相似的距离间隔,可以近似认为标签中心位置就是骨骼点的位置,距离即与骨骼相同。
为什么要说上述两种特点呢?这就要讲讲(吐槽)我在模型训练过程中发现的问题了。
模型概述
实现思路
对于该项目,我是根据一篇论文《PointSkelCNN: Deep Learning-Based 3D Human Skeleton Extraction from Point Clouds》 的思路进行了。作者认为,人体点云可以分成两部分:ambiguous point clouds和interest point clouds,ambiguous point clouds表示的是两个骨骼之间的点云,作者认为该部分的点云对姿态估计没有太多的作用(包括后面的测试结果也可以看出,包含了ambiguous point clouds的训练准确度要略低一些),关键的是离骨骼距离较近的点云。该论文利用CNN,在stage1的主要工作是训练一个二分类模型,将这两个部分进行分割,就可以获得人体点云的18部分的interest point clouds(虽然这个使用并不知道每个点云对应的部位),在stage2中再对于这部分点云进行训练,获得每个点云对应的向量值,指向对应的骨骼点,叠加在原点云上就可以通过DBSCAN求出聚类中心,也就是要求的骨骼位置。
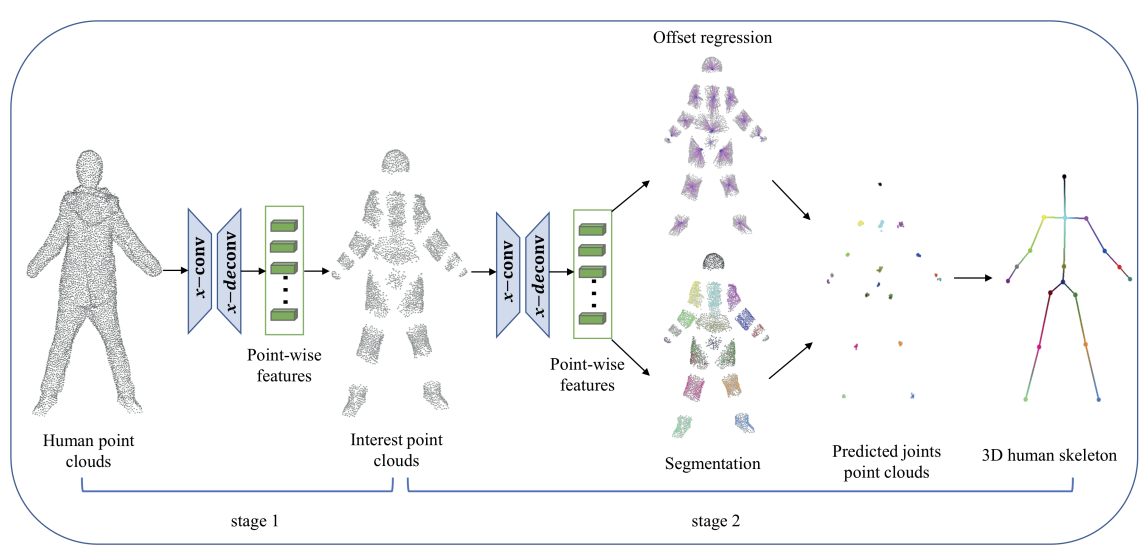
image-20240520091714351
我参考了论文的思路,但没有完全按照一样的方法操作(只是复现真的很无聊啊喂)
首先是对于两种类型的点的分割,感觉网络真的可以在无视骨骼特征的同时去除ambiguous point clouds吗?如果网络本身就是在学习骨骼特征,那在实现的过程中顺便给点云分配对应的标签不也可以吗?在对其进行分类后,用更精确的标签信息补充给网络,理论上来说最后骨骼应该会更加准确才对,或者说可以节省更多的训练时间就可以收敛。
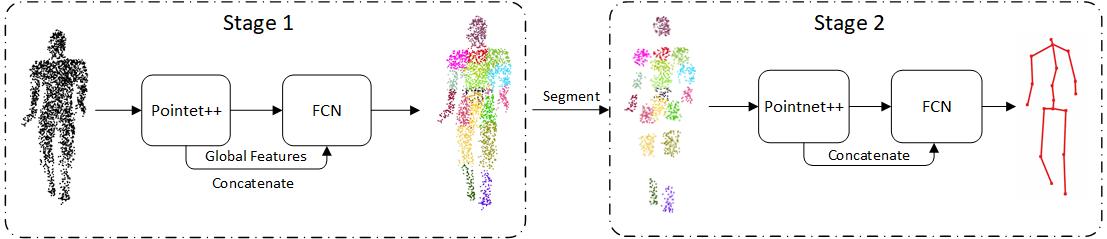
所以我希望可以尝试这样的过程:首先依据点云距离最近的骨骼,为点云分配标签,也就是0-17,对应18个骨骼点,然后根据每一类的中心位置,去除距离大于中位数的点,就可以得到带有骨骼标签的interest point clouds;再对该部分数据进行处理,得到每个点的向量,与原点云位置叠加并计算聚类中心之后就可以得到对应的骨骼位置了。大概过程可以参考下图。
model
在第一部分中,输入点云数据,并利用Pointnet++模型作为编码器,并将特征用FCN(全连接神经网络)进行处理,将人体分割成18个部分,每一个部分表示某个骨骼点周围存在的点云数据。在第二个模型中,将前一个模型中每个部分相邻的点云进行去除(也就是ambiguity points),将保留的点云(也就是interest points)输入到Pointnet++中进行处理,并用FCN输出对应的18个骨骼点的坐标位置。
Stage1 实现过程
pointnet++有一个用pytorch重新实现的代码,修改起来简单不少。 Pytorch Implementation of PointNet and PointNet++
在部署了pointnet++框架之后,简单处理了一下点云数据的输入。将人体点云通过均匀下采样控制在相近的范围内(点云采样无法做到精确数值,且较大程度的下采样可能会导致数据大幅缺失),再通过随机获取固定数量的点云数据作为点云输入(每次获取有一定数量的不同,一方面保证点云输入数量相同,另一方面有利于提高模型泛化能力)。
在确定模型训练代码及点云数据基本没问题后,先在本地电脑上利用较小的数据集训练模型(训练集大约512,验证集128 大了电脑确实跑不了了),并调整学习率、网络结构(MSG层、特征卷积层)等,观察模型的准确率、IOU等标准。
在开始的分类中我发现,如果直接进行18分类,准确率异常低(大约只有55%很多情况甚至都到不了)。为了找到原因,我将人体重新划分为5个部分(左侧手臂、右侧手臂、左腿、右腿、脊柱)重新进行训练,发现准确率一下就可以达到80%甚至更高。之后又将人体分成上半部分和下班部分进行二分类,准确率一下就可以提升到90%。这就考虑应该是特征提取不足所导致的问题了。
基于该情况,修改了点云输入数据,增加了法线数据。测试后发现进行18分类时大约有5%的提升(准确率接近60%),5分类可以达到88%。因此,可以认为确实是由于特征提取不足导致的,随后又添加了近邻点云距离的参数,表示每个点云距离最近10个点云的平均距离。此时5分类准确率达到92%,18分类达到65%。考虑到运行速度,使用了KD树重写了最近邻算法,将距离搜索速度提高了四倍以上(加载速度由15-16s/batch提升至3-4s/batch),并添加了表示最近20、50、100个点云的平均距离的维度。不过5分类和18分类均大约提升了1%,并不明显。
针对这种情况,认为在目前数据量的情况下很难有进一步的提升,且点云特征基本只有这些数据可以通用,所以只能考虑进一步修改模型。模型结构很难修改,但是可以修改loss函数,添加模型的约束项。也就是根据上面说到的两种特征,为模型添加约束项,在loss函数中按照上面的特征思路进行约束。通过训练后发现18分类最高可以达到88%的准确率,已经初步达到需求。特别是当去除模糊值后,点云的准确率甚至达到95%,相较来说还是可以使用的。
分类效果
真实分类结果
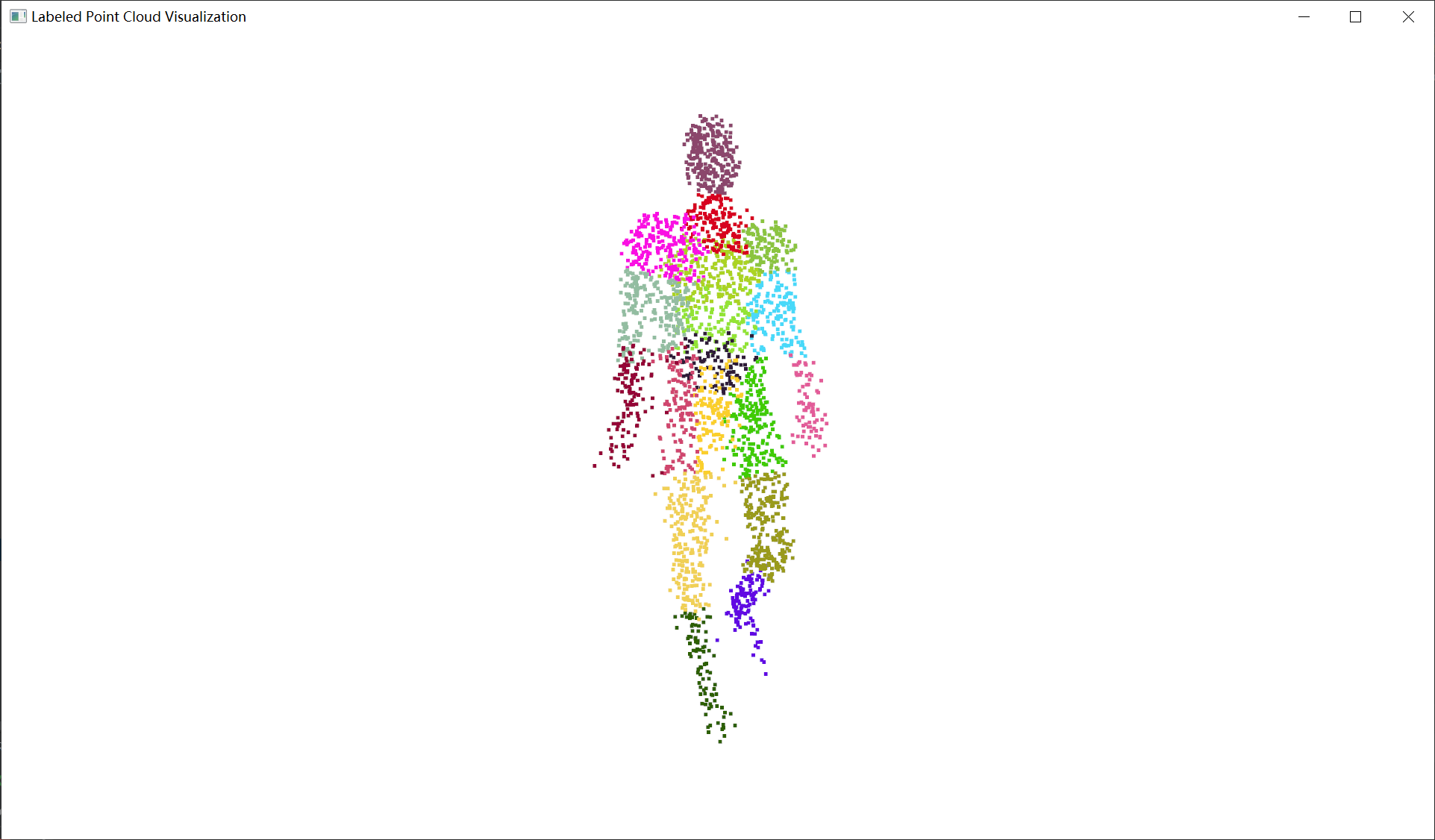
预测分类结果
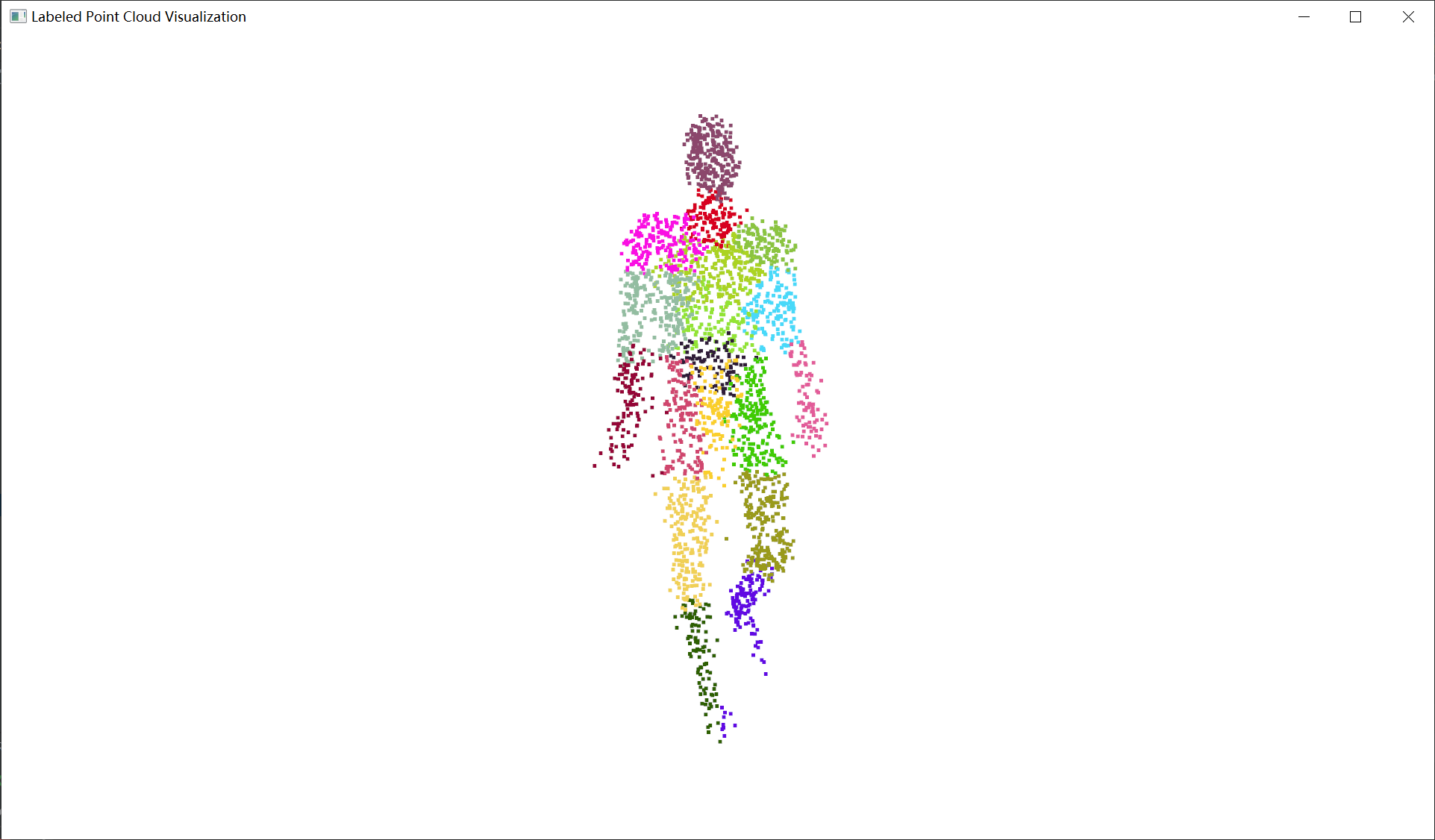
真实分类结果(分割)

预测分类结果(分割)

Stage2 实现过程
在stage 1的基础上,对于stage2的模型进行了测试。这里实际上进行了两种类型的网络测试。第一种是通过分割后的点云直接得到输出骨骼的空间位置,在服务器上训练后,表现最好的平均误差距离大约为7.3cm。相对于其他方法的模型来说有一定的提升,但考虑到原论文的结果以及项目对于准确度的追求,可能精度需要保持在5cm之内才能接受。
随后尝试了论文提到的方法,将点云及法线、标签等数据作为输入,输出每个点云对应的向量,将点云与向量叠加后可以得到一系列指向骨骼的坐标,通过求解每个标签对应坐标的中心距离,就可以得到该标签对应的骨骼位置。在尝试了该模型并简单修改了网络结构后,平均误差距离降到了3cm以内。在本地的测试集上随机选取了部分数据进行测试后,发现误差基本在4.5cm左右,认为基本可以接受。
输出结果
在UBC3V标准数据集上,stage1的模型准确率达到89%,stage2的模型在MPJPE指标(”Mean Per Joint Position Error”,即“平均(每)关节位置误差”,计算预测关节点与对应关节点的L2距离的平均值数值,越小表示骨骼点位置越精确)上的精度达到2.7101cm,接近原论文中的结果(原论文最高精度为2.16cm)不是他们网络怎么写的改了好多次模型换了好多策略根本达不到,但超越了其他类似方法(APGVD17:5.3cm,SL16:5.64cm)。



预览: